Every morning my team gets a message in Slack. It lists unanswered questions from other teams, stale pull requests, blocked sprint items, unassigned critical bugs, and anything that happened yesterday that the team should know about. Once a week, a longer version adds sprint health, PR quality checks, and a “challenge corner” that asks uncomfortable questions about stuck work.
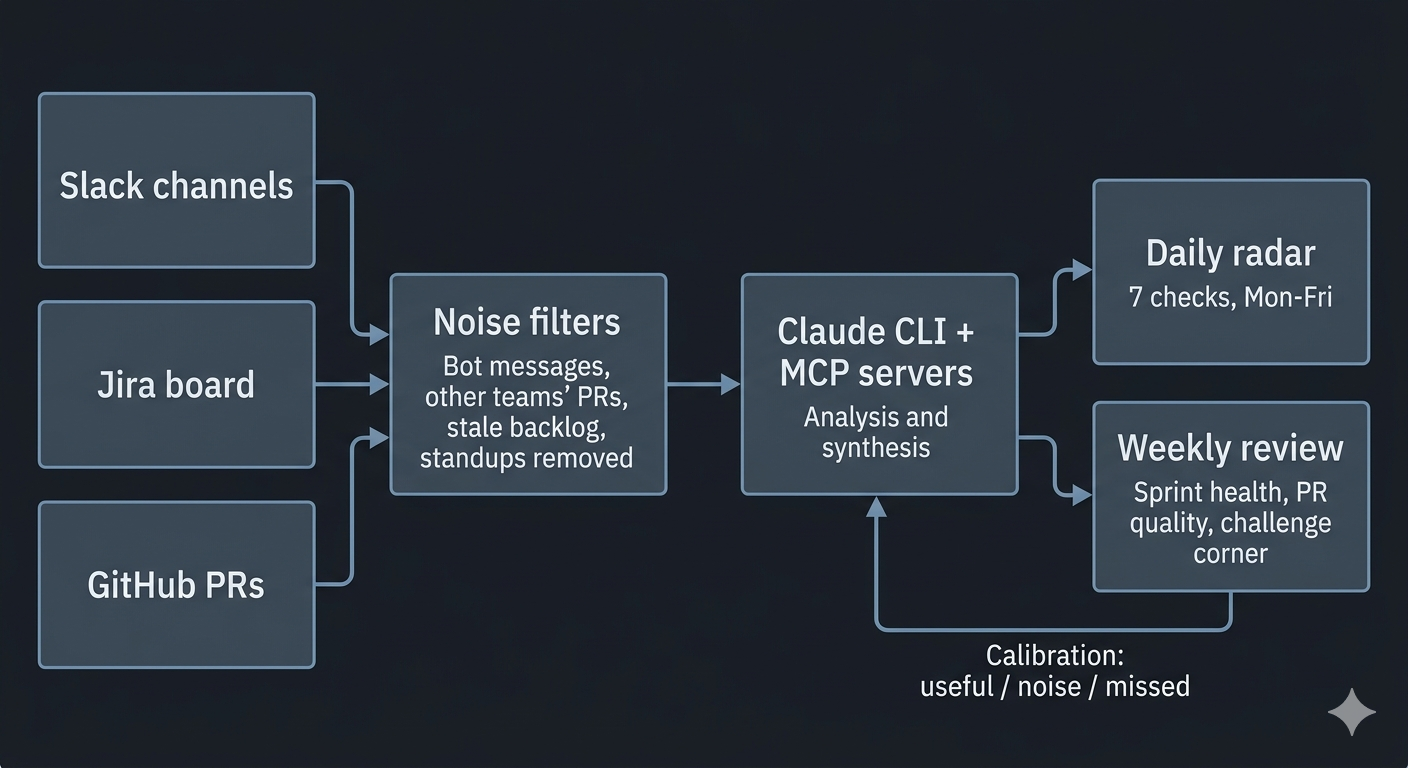
I didn’t write any of this manually. An LLM agent reads our Slack channels, Jira board, and GitHub PRs, filters out the noise, and assembles a briefing. The whole thing runs on Claude CLI with MCP servers for Slack, Jira, and GitHub access, triggered by a shell script.
Why I built it
The problem wasn’t that information was missing. It was scattered. A question from another team sits unanswered in Slack for a week. A PR gets approved but never merged for 23 days. A critical bug sits in triage with no owner. A technical decision gets made in a thread that three people saw.
None of these are crises. But with a big team, things naturally get missed or forgotten. And they’re invisible until someone complains or something breaks.
I used to catch some of this manually. Check Slack, scan the board, glance at PRs. But I’d miss things, and I could only do it for channels I actively watched. The agent checks everything, every day, consistently.
What the daily radar covers
Seven checks, run every weekday morning:
- Unanswered external requests. Other teams asking us questions in our public Slack channel with zero replies after 24 hours. Easy to miss in a busy channel.
- Blockers and criticals without owners. Unassigned critical bugs or items stuck in triage. Only from the active sprint, not the backlog.
- Stale PRs. Open, non-draft PRs with no merge after 5+ days. Lists age, author, review count.
- Release status. If a release is in flight, a one-liner with its status and any blocking bugs.
- Unanswered questions in Jira. Sprint tickets where someone asked a question in the comments and got no reply for 2+ days. These block work just like Slack threads, but they’re less visible.
- Yesterday’s key decisions. Architecture decisions, API changes, process changes from yesterday’s Slack threads. One-liner summary with a link.
- Cross-team dependencies. Who’s waiting on us, who we’re waiting on, and for how long.
The Slack message is a 3-7 bullet teaser with severity indicators (red for overdue, orange for risks, yellow for concerns). Full details go in an attached document.
What the weekly review adds
The weekly version runs on Monday mornings and adds five more checks:
- Sprint health. Percentage of items in To Do vs In Progress vs Done. Flags if more than half the sprint is still in To Do past the midpoint.
- Stuck work. Sprint items “In Progress” with no update for 7+ days, or in QA queue for 3+ days.
- PR quality. Merged PRs from the past week checked for: no tests, rubber-stamped approvals, empty descriptions, scope creep, leftover TODOs, oversized diffs without breakdown.
- Decision follow-up. Decisions from previous weeks that have a follow-up date. Did the expected action happen?
- Challenge corner. 1-3 observations phrased as questions. “This critical bug has been unassigned for 5 days, who owns it?” “This compliance thread has been open 5 weeks, still active or needs escalation?” “Dev environment broke 3 times in 6 weeks per the same reporter, systemic issue?”
The challenge corner was the hardest part to get right. The difference between useful and annoying is tone. Questions, not accusations. “Who owns this?” not “Nobody is working on this.”
The noise problem
The raw signal from Slack, Jira, and GitHub is mostly noise. Bot messages, automated config diffs, other teams’ PRs in our shared monorepo, stale backlog items from two years ago.
I spent more time on filters than on the actual analysis logic:
- Firebase config bot diffs (about 12% of our dev channel volume): filtered out.
- Auto-sync bot PRs in our monorepo (about 64% of all PR volume): filtered out.
- Other teams’ PRs in the shared repo: filtered by author list and ticket prefix.
- Stale backlog items: excluded entirely. Backlog health is a separate quarterly exercise, not a daily concern.
- Standup updates, go/no-go votes, process posts: all excluded.
Without these filters, every daily radar would be 80% noise and the team would stop reading it within a week.
Design principles that matter
All sources or no report. If any data source (Slack, Jira, GitHub) is unavailable, the agent stops entirely. A partial radar with missing sections is worse than no radar, because it creates blind spots that look like “nothing to flag.”
Quality over quantity. If there’s nothing to share, no message gets sent. Never spam the team with “all clear” reports just to prove the system is running.
No automation until calibrated. I ran it manually for weeks first, shared results privately with tech leads, and tuned thresholds based on their feedback (“this is useful” / “this is noise” / “you missed X”). Only after the signal-to-noise ratio was right did I automate it.
That last one was the most important decision. Shipping an automated digest that’s 30% noise on day one would have killed trust in the tool permanently. The manual calibration period let me learn what the team actually cares about before committing to a cadence.
Decision tracking
One thing I didn’t expect to become important: tracking decisions.
Technical decisions happen in Slack threads. Someone proposes a change, a few people discuss it, someone says “let’s do it,” and the thread scrolls away. Two months later nobody remembers whether it was decided, implemented, or abandoned.
The agent logs every decision it spots into a tracking file. Each entry has: what was decided, who decided it, a link to the source, what action is expected, and a follow-up date. The weekly digest checks open decisions past their follow-up date.
When decisions cluster around a topic (three or more about release quality, for example), the weekly digest flags it as a candidate for a process document. Decisions graduate from scattered Slack threads to a single source of truth.
What it gets wrong
The agent misses context that lives in people’s heads. It’ll flag a PR as stale when the author is on vacation. It’ll surface a “blocked” ticket that’s actually waiting on a deliberate hold. It doesn’t know that someone already escalated a dropped thread in a DM.
The response time thresholds are blunt instruments. 24 hours for Slack, 2 days for Jira comments, 5 days for PRs. Some things are genuinely fine to sit for a week. Others need a response in an hour. The agent can’t tell the difference.
And the challenge corner occasionally asks questions that make people defensive, despite the careful phrasing. “This has been blocked for 10 days” can still feel like “why hasn’t anyone fixed this” regardless of how you word it.
I’ve learned to treat the radar as a starting point for conversation, not a scoreboard. The team knows it’s a tool, not a manager.